Pandas必备技能之“时间序列数据处理”
时间序列数据Time Series Data是在不同时间上收集到的数据,这类数据是按时间顺序收集到的,用于所描述现象随时间变化的情况。
时间序列分析广泛应用于计量经济学模型中,通过寻找历史数据中某一现象的发展规律,对未来进行预测。
时间序列数据作为时间序列分析的基础,学会如何对它进行巧妙地处理是非常必要的,Python中的Pandas库为我们提供了强大的时间序列数据处理的方法,本文会介绍其中常用的几个。
【工具】
- Python 3
- Tushare
01、时间格式转换
有时候,我们获得的原始数据并不是按照时间类型索引进行排列的,需要先进行时间格式的转换,为后续的操作和分析做准备。
这里介绍两种方法。第一种方法是用pandas.read_csv导入文件的时候,通过设置参数parse_dates和index_col,直接对日期列进行转换,并将其设置为索引。关于参数的详细解释,请查看文档【1】。
如下示例中,在没有设置参数之前,可以观察到数据集中的索引是数字0-208,'date'列的数据类型也不是日期。
- In [8]: data = pd.read_csv('unemployment.csv')
- In [9]: data.info()
- <class 'pandas.core.frame.DataFrame'>
- RangeIndex: 209 entries, 0 to 208
- Data columns (total 2 columns):
- date 209 non-null object
- UNRATE 209 non-null float64
- dtypes: float64(1), object(1)
- memory usage: 3.3+ KB
设置参数parse_dates = ['date'] ,将数据类型转换成日期,再设置 index_col = 'date',将这一列用作索引,结果如下。
- In [11]: data = pd.read_csv('unemployment.csv', parse_dates=['date'], index_col='date')
- In [12]: data.info()
- <class 'pandas.core.frame.DataFrame'>
- DatetimeIndex: 209 entries, 2000-01-01 to 2017-05-01
- Data columns (total 1 columns):
- UNRATE 209 non-null float64
- dtypes: float64(1)
- memory usage: 13.3 KB
这时,索引变成了日期'20000101'-'2017-05-01',数据类型是datetime。
第二种方法是在已经导入数据的情况下,用pd.to_datetime()【2】将列转换成日期类型,再用 df.set_index()【3】将其设置为索引,完成转换。
以tushare.pro上面的日线行情数据为例,我们把'trade_date'列转换成日期类型,并设置成索引。
- import tushare as ts
- import pandas as pd
- pd.set_option('expand_frame_repr', False) # 列太多时不换行
- pro = ts.pro_api()
- df = pro.daily(ts_code='000001.SZ', start_date='20180701', end_date='20180718')
- df.info()
- <class 'pandas.core.frame.DataFrame'>
- RangeIndex: 13 entries, 0 to 12
- Data columns (total 11 columns):
- ts_code 13 non-null object
- trade_date 13 non-null object
- open 13 non-null float64
- high 13 non-null float64
- low 13 non-null float64
- close 13 non-null float64
- pre_close 13 non-null float64
- change 13 non-null float64
- pct_chg 13 non-null float64
- vol 13 non-null float64
- amount 13 non-null float64
- dtypes: float64(9), object(2)
- memory usage: 1.2+ KB
- None
- df['trade_date'] = pd.to_datetime(df['trade_date'])
- df.set_index('trade_date', inplace=True)
- df.sort_values('trade_date', ascending=True, inplace=True) # 升序排列
- df.info()
- <class 'pandas.core.frame.DataFrame'>
- DatetimeIndex: 13 entries, 2018-07-02 to 2018-07-18
- Data columns (total 10 columns):
- ts_code 13 non-null object
- open 13 non-null float64
- high 13 non-null float64
- low 13 non-null float64
- close 13 non-null float64
- pre_close 13 non-null float64
- change 13 non-null float64
- pct_chg 13 non-null float64
- vol 13 non-null float64
- amount 13 non-null float64
- dtypes: float64(9), object(1)
- memory usage: 1.1+ KB
打印出前5行,效果如下。
- df.head()
- Out[15]:
- ts_code open high low close pre_close change pct_chg vol amount
- trade_date
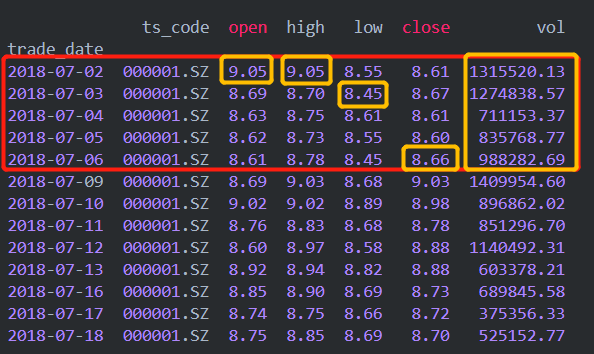
- 2018-07-02 000001.SZ 9.05 9.05 8.55 8.61 9.09 -0.48 -5.28 1315520.13 1158545.868
- 2018-07-03 000001.SZ 8.69 8.70 8.45 8.67 8.61 0.06 0.70 1274838.57 1096657.033
- 2018-07-04 000001.SZ 8.63 8.75 8.61 8.61 8.67 -0.06 -0.69 711153.37 617278.559
- 2018-07-05 000001.SZ 8.62 8.73 8.55 8.60 8.61 -0.01 -0.12 835768.77 722169.579
- 2018-07-06 000001.SZ 8.61 8.78 8.45 8.66 8.60 0.06 0.70 988282.69 852071.526
02、时间周期转换
在完成时间格式转换之后,我们就可以进行后续的日期操作了。下面介绍一下如何对时间序列数据进行重采样resampling。
重采样指的是将时间序列从⼀个频率转换到另⼀个频率的处理过程。将⾼频率数据聚合到低频率称为降采样downsampling,如将股票的日线数据转换成周线数据,⽽将低频率数据转换到⾼频率则称为升采样upsampling,如将股票的周线数据转换成日线数据。
降采样:以日线数据转换周线数据为例。继续使用上面的tushare.pro日线行情数据,选出特定的几列。
- df = df[['ts_code', 'open', 'high', 'low', 'close', 'vol']] # 单位:成交量 (手)
- ts_code open high low close vol
- trade_date
- 2018-07-02 000001.SZ 9.05 9.05 8.55 8.61 1315520.13
- 2018-07-03 000001.SZ 8.69 8.70 8.45 8.67 1274838.57
- 2018-07-04 000001.SZ 8.63 8.75 8.61 8.61 711153.37
- 2018-07-05 000001.SZ 8.62 8.73 8.55 8.60 835768.77
- 2018-07-06 000001.SZ 8.61 8.78 8.45 8.66 988282.69
- 2018-07-09 000001.SZ 8.69 9.03 8.68 9.03 1409954.60
- 2018-07-10 000001.SZ 9.02 9.02 8.89 8.98 896862.02
- 2018-07-11 000001.SZ 8.76 8.83 8.68 8.78 851296.70
- 2018-07-12 000001.SZ 8.60 8.97 8.58 8.88 1140492.31
- 2018-07-13 000001.SZ 8.92 8.94 8.82 8.88 603378.21
- 2018-07-16 000001.SZ 8.85 8.90 8.69 8.73 689845.58
- 2018-07-17 000001.SZ 8.74 8.75 8.66 8.72 375356.33
- 2018-07-18 000001.SZ 8.75 8.85 8.69 8.70 525152.77
为了方便大家观察,把这段时间的日历附在下面,'2018-07-02'正好是星期一。
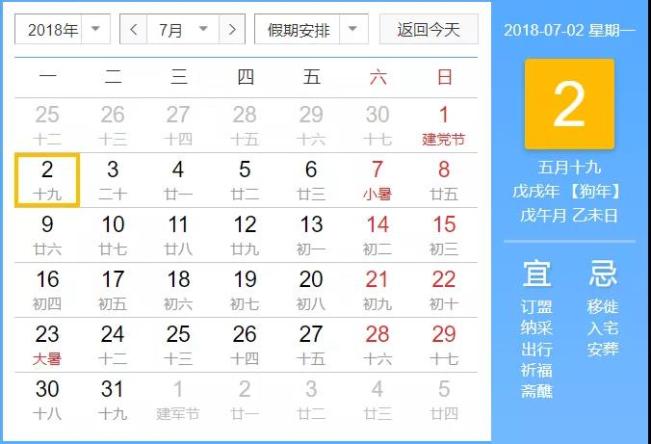
转换的思路是这样的,以日历中的周进行聚合,如'20180702'-'20180708',取该周期内,日线开盘价的第一个值作为周开盘价,日线最高价的最大值作为周最高价,日线最低价的最小值作为周最低价,日线收盘价的最后一个值作为周最收盘价,日线最高价的最大值作为周最高价,日线成交量的求和作为周成交量(手),如下图黄色方框所示。
我们可以通过.resample()【4】方法实现上述操作,对DataFrame和Series都适用。其中,参数rule设置需要转换成的频率,'1W'是一周。
具体转换的代码如下,日期默认为本周的星期日,如果周期内数据不全,如'20180722'这周只有3行数据,也会按照上述方法进行转换。
- freq = '1W'
- df_weekly = df[['open']].resample(rule=freq).first()
- df_weekly['high'] = df['high'].resample(rule=freq).max()
- df_weekly['low'] = df['low'].resample(rule=freq).min()
- df_weekly['close'] = df['close'].resample(rule=freq).last()
- df_weekly['vol'] = df['vol'].resample(rule=freq).sum()
- df_weekly
- Out[33]:
- open high low close vol
- trade_date
- 2018-07-08 9.05 9.05 8.45 8.66 5125563.53
- 2018-07-15 8.69 9.03 8.58 8.88 4901983.84
- 2018-07-22 8.85 8.90 8.66 8.70 1590354.68
升采样:以周线数据转换日线数据为例。继续使用上面刚刚转换好的周线数据,我们再试着把它转换成日线数据。先通过.resample('D').asfreq()【5】方法,将周线数据的频率转换成日线,效果如下。
- df_daily = df_weekly.resample('D').asfreq()
- print(df_daily)
- Out[52]:
- open high low close vol
- trade_date
- 2018-07-08 9.05 9.05 8.45 8.66 5125563.53
- 2018-07-09 NaN NaN NaN NaN NaN
- 2018-07-10 NaN NaN NaN NaN NaN
- 2018-07-11 NaN NaN NaN NaN NaN
- 2018-07-12 NaN NaN NaN NaN NaN
- 2018-07-13 NaN NaN NaN NaN NaN
- 2018-07-14 NaN NaN NaN NaN NaN
- 2018-07-15 8.69 9.03 8.58 8.88 4901983.84
- 2018-07-16 NaN NaN NaN NaN NaN
- 2018-07-17 NaN NaN NaN&nnbsp; NaN NaN
- 2018-07-18 NaN NaN NaN NaN NaN
- 2018-07-19 NaN NaN NaN NaN NaN
- 2018-07-20 NaN NaN NaN NaN NaN
- 2018-07-21 NaN NaN NaN NaN NaN
- 2018-07-22 8.85 8.90 8.66 8.70 1590354.68
结果中出现了很多空值,需要我们按照一定的方法进行填充,可以通过添加.ffill()或者.bfill()实现。
其中,.ffill()代表用前值进行填充,也就是用前面的非空值对后面的NaN值进行填充,如'20180709'-20180714' 的NaN值都等于'20180708'这一行的非空值,效果如下。
- df_daily = df_weekly.resample('D').ffill()
- df_daily
- Out[54]:
- open high low close vol
- trade_date
- 2018-07-08 9.05 9.05 8.45 8.66 5125563.53
- 2018-07-09 9.05 9.05 8.45 8.66 5125563.53
- 2018-07-10 9.05 9.05 8.45 8.66 5125563.53
- 2018-07-11 9.05 9.05 8.45 8.66 5125563.53
- 2018-07-12 9.05 9.05 8.45 8.66 5125563.53
- 2018-07-13 9.05 9.05 8.45 8.66 5125563.53
- 2018-07-14 9.05 9.05 8.45 8.66 5125563.53
- 2018-07-15 8.69 9.03 8.58 8.88 4901983.84
- 2018-07-16 8.69 9.03 8.58 8.88 4901983.84
- 2018-07-17 8.69 9.03 8.58 8.88 4901983.84
- 2018-07-18 8.69 9.03 8.58 8.88 4901983.84
- 2018-07-19 8.69 9.03 8.58 8.88 4901983.84
- 2018-07-20 8.69 9.03 8.58 8.88 4901983.84
- 2018-07-21 8.69 9.03 8.58 8.88 4901983.84
- 2018-07-22 8.85 8.90 8.66 8.70 1590354.68
同理,.bfill()代表用后值对空值进行填充,效果如下。
- df_daily = df_weekly.resample('D').bfill()
- df_daily
- Out[55]:
- open high low close vol
- trade_date
- 2018-07-08 9.05 9.05 8.45 8.66 5125563.53
- 2018-07-09 8.69 9.03 8.58 8.88 4901983.84
- 2018-07-10 8.69 9.03 8.58 8.88 4901983.84
- 2018-07-11 8.69 9.03 8.58 8.88 4901983.84
- 2018-07-12 8.69 9.03 8.58 8.88 4901983.84
- 2018-07-13 8.69 9.03 8.58 8.88 4901983.84
- 2018-07-14 8.69 9.03 8.58 8.88 4901983.84
- 2018-07-15 8.69 9.03 8.58 8.88 4901983.84
- 2018-07-16 8.85 8.90 8.66 8.70 1590354.68
- 2018-07-17 8.85 8.90 8.66 8.70 1590354.68
- 2018-07-18 8.85 8.90 8.66 8.70 1590354.68
- 2018-07-19 8.85 8.90 8.66 8.70 1590354.68
- 2018-07-20 8.85 8.90 8.66 8.70 1590354.68
- 2018-07-21 8.85 8.90 8.66 8.70 1590354.68
- 2018-07-22 8.85 8.90 8.66 8.70 1590354.68
03、时间窗口函数
当我们想要比较数据在相同时间窗口的不同特征和变化时,可以借助窗口函数rolling【6】进行计算。
看一个实例:计算股票收盘价的移动平均值。
- df = df[['ts_code', 'close']]
- df
- Out[58]:
- ts_code close
- trade_date
- 2018-07-02 000001.SZ 8.61
- 2018-07-03 000001.SZ 8.67
- 2018-07-04 000001.SZ 8.61
- 2018-07-05 000001.SZ 8.60
- 2018-07-06 000001.SZ 8.66
- 2018-07-09 000001.SZ 9.03
- 2018-07-10 000001.SZ 8.98
- 2018-07-11 000001.SZ 8.78
- 2018-07-12 000001.SZ 8.88
- 2018-07-13 000001.SZ 8.88
- 2018-07-16 000001.SZ 8.73
- 2018-07-17 000001.SZ 8.72
- 2018-07-18 000001.SZ 8.70
调用rolling函数,通过设置参数window的值规定窗口大小,这里设置为3,并且调用.mean()方法计算窗口期为3天的均值,结果如下。
其中,'20180704'当天的平均值等于'20180702'-'20180704'三天的收盘价取平均的结果,'20180705'当天的平均值等于'20180703'-'20180705'三天的收盘价取平均的结果,以此类推。
- df['MA3'] = df['close'].rolling(3).mean()
- df
- Out[76]:
- ts_code close MA3
- trade_date
- 2018-07-02 000001.SZ 8.61 NaN
- 2018-07-03 000001.SZ 8.67 NaN
- 2018-07-04 000001.SZ 8.61 8.630000
- 2018-07-05 000001.SZ 8.60 8.626667
- 2018-07-06 000001.SZ 8.66 8.623333
- 2018-07-09 000001.SZ 9.03 8.763333
- 2018-07-10 000001.SZ 8.98 8.890000
- 2018-07-11 000001.SZ 8.78 8.930000
- 2018-07-12 000001.SZ 8.88 8.880000
- 2018-07-13 000001.SZ 8.88 8.846667
- 2018-07-16 000001.SZ 8.73 8.830000
- 2018-07-17 000001.SZ 8.72 8.776667
- 2018-07-18 000001.SZ 8.70 8.716667
还有一个常用的窗口函数是expanding,每增加一行数据,窗口会相应的增大。比如,我们想计算某只股票每天的累计涨跌幅,就可以调用此函数。
- df = df[['ts_code', 'pct_chg']] # 列pct_chg单位是(%)
- Out[71]:
- ts_code pct_chg
- trade_date
- 2018-07-02 000001.SZ -5.28
- 2018-07-03 000001.SZ 0.70
- 2018-07-04 000001.SZ -0.69
- 2018-07-05 000001.SZ -0.12
- 2018-07-06 000001.SZ 0.70
- 2018-07-09 000001.SZ 4.27
- 2018-07-10 000001.SZ -0.55
- 2018-07-11 000001.SZ -2.23
- 2018-07-12 000001.SZ 2.78
- 2018-07-13 000001.SZ 0.00
- 2018-07-16 000001.SZ -1.69
- 2018-07-17 000001.SZ -0.11
- 2018-07-18 000001.SZ -0.23
对列'pct_chg'调用窗口函数expanding,再调用.sum()方法求累计值。
- df['cum_pct_chg'] = df['pct_chg'].expanding().sum()
- df
- Out[78]:
- ts_code pct_chg cum_pct_chg
- trade_date
- 2018-07-02 000001.SZ -5.28 -5.28
- 2018-07-03 000001.SZ 0.70 -4.58
- 2018-07-04 000001.SZ -0.69 -5.27
- 2018-07-05 000001.SZ -0.12 -5.39
- 2018-07-06 000001.SZ 0.70 -4.69
- 2018-07-09 000001.SZ 4.27 -0.42
- 2018-07-10 000001.SZ -0.55 -0.97
- 2018-07-11 000001.SZ -2.23 -3.20
- 2018-07-12 000001.SZ 2.78 -0.42
- 2018-07-13 000001.SZ 0.00 -0.42
- 2018-07-16 000001.SZ -1.69 -2.11
- 2018-07-17 000001.SZ -0.11 -2.22
- 2018-07-18 000001.SZ -0.23 -2.45
04、总结
本文介绍了Pandas库中处理时间序列数据的几种常用方法。
在时间格式转换部分,介绍了两种将时间转化成日期类型的方法,分别是通过设置参数parse_dates和调用方法pd.to_datetime()。
接着,介绍了时间周期的转换,通过调用.resample()方法实现,包括降采样和升采样。
最后,介绍两个常用的窗口函数rolling和expanding。
希望大家能灵活掌握本文中提到的方法,并应用到实际工作和学习中去!
译者简介:
Little monster,北京第二外国语学院国际商务专业研一在读,目前在学习Python编程和量化投资相关知识。

时间:2019-06-14 00:06 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
















