不会聊天的程序员,如何开发聊天机器人
不会聊天的人能开发聊天机器人吗?如果开发者自己就不会聊天,开发出来的机器人是不是也不会聊天呢?
ELIZA:聊天机器人的鼻祖
我们先来看看世界上第一款聊天机器人吧:1966 年,在 MIT 任职的德裔美国计算机科学家 Joseph Weizenbaum,开发出了一款名为 ELIZA 的聊天机器人程序。
通过运行名为 DOCTOR 的脚本,此程序可以用类似心理学家的方式和人类交谈。下面就是一段 ELIZA 和用户的经典对话:
User: Men are all alike.
ELIZA: IN WHAT WAY
User: They’re always bugging us about something or other.
ELIZA: CAN YOU THINK OF A SPECIFIC EXAMPLE
User: Well, my boyfriend made me come here.
ELIZA: YOUR BOYFRIEND MADE YOU COME HERE
User: He says I’m depressed much of the time.
ELIZA: I AM SORRY TO HEAR YOU ARE DEPRESSED
User: Men are all alike.
ELIZA: IN WHAT WAY
User: They’re always bugging us about something or other.
ELIZA: CAN YOU THINK OF A SPECIFIC EXAMPLE
User: Well, my boyfriend made me come here.
ELIZA: YOUR BOYFRIEND MADE YOU COME HERE
User: He says I’m depressed much of the time.
ELIZA: I AM SORRY TO HEAR YOU ARE DEPRESSED
好暖心的 ELIZA(不是 ELSA),和“她”说话,是不是感觉很治愈?
“她”的制造者引入了心理学家罗杰斯提出的个人中心疗法(Person-Centered Therapy),更多强调对话态度、尊重与同理心。Eliza 并不主动提供内容,它只是引导用户说话。
那么 ELIZA 背后的计算逻辑是什么样的呢?
简单得叫人想哭,其实就是一条条模式匹配和字符替换规则,下面是其中几条:
you are (depressed|sad) * => I AM SORRY TO HEAR YOU ARE 1all * => IN WHAT WAYalways * => CAN YOU THINK OF A SPECIFIC EXAMPLE
用户说失望/伤心,ELIZA 就回答“我好抱歉啊”;用户用了“所有”这个词,机器人就追问一句“以何种方式”;如果用户说“总是”如何如何, 程序就引导“你能举个例子吗”……
ELIZA 项目取得了意外的成功,它的效果让当时的用户非常震惊。Joseph 教授原本希望 ELIZA 能够伪装成人,但没有寄予太高期望,让他没想到的是,这个伪装居然很多次都成功了,而且还不容易被拆穿。以致于后来产生一个词汇,叫 ELIZA 效应,即人类高估机器人能力的一种心理感觉。
ELIZA 无疑是一款会聊天的机器人——很多程序员真应该和 ELIZA 好好学学:跟人说话的时候经常重复一下对方的话,以显示同理心;经常跟进询问“到底是怎么回事呢?”,“你能举个例子吗?”以显示对对方的尊重和关注;经常说“好的”,“是的”,“你是对的”,自然就获得对方的好感了……
但是,这样一款机器人,真的能解决现实的问题吗?如果,我需要的不是和人闲聊,而是需要确定,或者咨询某件事,机器人能告诉我吗?
对于这样的需求,ELIZA 恐怕做不到,不过,别的机器人可以。
问题解决型机器人
Task Completion Bot
问题解决型机器人,存在的目的是为了帮用户解决具体问题,例如:售前咨询、售后报修、订机票、酒店、餐厅座位等等。
基础三步
和 ELIZA 明显不同,问题解决型机器人需要提供给用户用户自己都不知道的信息。
有鉴于此,问题解决型机器人(TC Bot)需要有自己的知识储备——知识库(Knowledge Base),其中存储的信息用来提供给用户。
光有了知识还不够,还需要至少做到两件事:
有了这三者,就可以做到最基本的问题解决了:

多轮对话的上下文管理
如果用户的每个问题都是完整的,包含了该问题所需要的所有信息,当然上面三步就可以得出答案。
不过人类在聊天的时候有个习惯,经常会把部分信息隐含在上下文中,比如下面这段对话:
提问:今天北京多少度啊?
回答:35度。
提问:有雾霾吗?(北京有雾霾吗?)
回答:空气质量优。
提问:那上海呢?(上海有雾霾吗?)
回答:空气质量也是优。
提问:今天北京多少度啊?
回答:35度。
提问:有雾霾吗?(北京有雾霾吗?)
回答:空气质量优。
提问:那上海呢?(上海有雾霾吗?)
回答:空气质量也是优。
人类理解起来很容易,但是如果要让机器人理解,我们就需要给它添加上一个专门的上下文管理模块,用来记录上下文。
如此一来,支持多轮对话的问题解决型聊天机器人,就需要经历下列四步来完成。
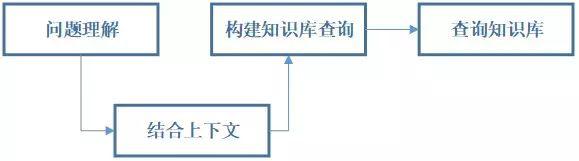
分层结构
从程序开发的角度,TC Bot 分为三层:

-
输入输出:
- 接受、理解用户问题
- 生成、返回答案给用户
-
中间控制:构建双向关系
- 用户问题=>知识库知识
- 知识库知识=>机器人答案
- 知识存储:存储用于回答用户问题的知识。
- 接受、理解用户问题
- 生成、返回答案给用户
- 用户问题=>知识库知识
- 知识库知识=>机器人答案
聊天机器人的实现技术
从学术研究的角度讲,聊天机器人所需技术涉及到自然语言处理、文本挖掘、知识图谱等众多领域。
当前的研究和实践中,大量机器学习、深度学习技术被引入。各种炫酷的算法模型跑在 Google、微软等IT寡头的高质量数据上,得到了颇多激动人心的研究成果。
但具体到实践当中,在没有那么巨量的人工标注数据和大规模计算资源的情况下,于有限范围(scope)内,开发一款真正有用的机器人,更多需要关注的往往不是高深的算法和强健的模型,而是工程细节和用户体验。
此处,我们只是简单介绍几种当前实践中最常用,且相对简单的方法:
Solution 1:用户问题->标准问题->答案
知识库中存储的是一对对的“问题-答案”对(QA Pair)。这些Pair可以是人工构建的,源于专家系统或者旧有知识库的,也可以是从互联网上爬取下来的。
现在互联网资源这么丰富,各种网页上到处都是 FAQ,Q&A,直接爬下来就可以导入知识库。以很小的代价就能让机器人上知天文下晓地理。
当用户输入问题后,将其和知识库现有的标准问题进行一一比对,寻找与用户问题最相近的标准问题,然后将该问题组对的答案返回给用户。
其中,用户问题->标准问题的匹配方法可以是关键词匹配(包括正则表达式匹配);也可以是先将用户问题和标准问题都转化为向量,再计算两者之间的距离(余弦距离、欧氏距离、交叉熵、Jaccard 距离等),找到距离最近且距离值低于预设阈值的那个标准问题,作为查找结果。
但关键字匹配覆盖面太小。距离计算的话,在实践中比对出来的最近距离的两句话,可能在语义上毫无关联,甚至满拧(比如一个比另一个多了一个否定词)。另外,确认相似度的阈值也很难有一个通用的有效方法,很多时候都是开发者自己拍脑袋定的。
因此,这种方案,很难达到高质高效。
Solution 2:用户问题->答案
知识库中存储的不是问题-答案对,而仅存储答案(文档)。
当接收到用户问题后,直接拿问题去和知识库中的一篇篇文档比对,找到在内容上关联最紧密的那篇,作为答案返回给用户。
这种方法维护知识库的成本更小,但相对于 Solution 1,准确度更低。
Solution 3:用户问题->语义理解->知识库查询->查询结果生成答案
相应的,知识库内存储的知识,除了包含知识内容本身之外,还应该在结构上能够表示知识之间的关联关系。
Chatbot 在提取了意图和实体后,构造出对知识库的查询(Query),实施查询,得出结果后生成回答,回复给用户。

时间:2020-04-07 10:59 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
















