AI 团队在创建 AI 数据时节省时间的 6 个关键最佳实践
所有 ML 团队共享的一件事是需要让他们的数据对他们的模型有用。涉足大量非结构化数据以准确注释资产需要大量的耐心、组织和时间。根据 Algorithmia 的 ML 调查状态,近 96% 的公司在投入生产时遇到延迟,78% 的机器学习项目在部署之前就停滞不前。加快速度是我们从客户那里听到的最大痛点;它控制着他们实现项目目标并获得优于竞争对手的优势的能力。速度不仅对于将模型投入生产至关重要,而且对于满足这些日益激进的期望的时间表也是必不可少的。
使用动态排队系统更快地注释
AI 团队可以通过使用动态排队系统将标记任务路由到正确的团队成员,从而使他们永远不会闲置,从而受益于更快的注释。借助动态排队,团队能够创建标签工作流,其中低置信度预测是可见的,并且他们的数据科学家和标签人员可以优先考虑。这使您可以更快速地分析和更正标签。
动态排队允许您通过自动将标记任务路由给正确的团队成员来节省时间。
- 只有活跃的贴标者才会被分配要注释的资产,以消除重复和等待
- 动态排队一次保留多个资产,以确保您的标签团队不会在资产之间等待
- 团队共享一个自动分配给贴标签者和审阅者的积压工作
改善团队之间的协作和共识
为了在标记过程中实现更好的协作,团队应该寻求实施流程和专用工具来轻松完成重复性任务,例如添加和澄清对标记资产的反馈。为了获得和澄清反馈,快速提出问题并在标记资产上添加评论的能力为将问题升级给审阅者或主题专家提供了一个简单而可靠的渠道。
贴标者可以创建问题来提出问题,尽其所能提交已完成的标签,并在标签审核过程中接收反馈和澄清。这种简化的标签协作方式为团队提供了一种快速处理标签过程中出现的不可避免问题的方法。
为了提高团队成员之间的共识,您可以使用共识工具快速推动团队达成一致,该工具可帮助您就好的外观达成共识。此工具允许您自动将给定资产上的注释与该资产上的所有其他注释进行比较。一致性是通过贴标者之间标签协议的平均值来衡量的。例如,当共识设置为 3 时,每个标签都由两个相似的标签分组,三个的平均值成为共识分数。
利用程序化方法更快地访问数据
团队现在可以通过 SDK 和/或 API 使用编程方法来加快数据导入和标记数据导出过程,而不是手动缓慢地处理数据传输方法。通过连接团队的数据和自动化批量操作,随着项目的复杂性随着时间的推移而增加,标记数据(包括所有元数据、数据集的创建方式以及标记器反馈)变得更加容易和更快地管理和跟踪。这种方法提供了端点灵活性,因此您可以在现有工作流程中插入和使用,而不会丢失训练数据的任何有价值的方面。
如何实现这一点的一个例子是使用Python SDK,它可以更好地控制您的数据,同时简化和加快数据导入。例如,它简化了数据导入过程,以便您可以使用批量 DataRow 创建。此过程是异步的,因此您不必等待批量创建完成即可继续执行其他任务(尽管您可以等待,如果您愿意)。在某些情况下,您还可以使用 Python SDK 以面向对象的方式以编程方式创建项目和数据集、导出标签并将元数据添加到资产中——完成对象之间的所有关系,从而加快您的标签工作流程。通过使用这种方法,您甚至可以自动导出新创建的训练数据以进行主动学习工作流程,并调整您的标签队列以专注于提高对特定课程的信心。
利用针对速度优化的软件
许多 ML 团队花费大量时间尝试为无法扩展的训练数据构建自定义基础架构,从而导致开发工作脱节。根据研究公司 Cognilytica 的数据,ML 团队花费高达 80% 的时间来构建和维护训练数据基础设施。
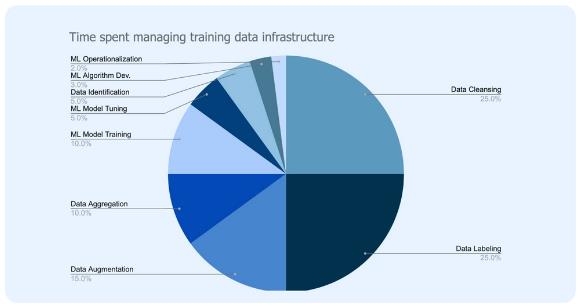
构建这样的定制基础设施既困难又昂贵,可能需要花费数百万美元的工程资源来构建和维护。作为一种节省时间的替代方案,许多团队通过采用训练数据平台 (TDP) 找到了答案。TDP 是专为提高处理 AI 数据的速度和易用性而设计的专用软件。它允许团队使用已经建立的最佳实践更快地行动,而不是使用本土工具和重新创建轮子。通过合并 TDP,团队在数据准备和标记方面节省了指数级时间,因此 ML 团队可以将更多时间用于他们的核心
能力:构建生产模型。
但并非所有 TDP 都是平等的。您可以在我们的TDP 101 指南中详细了解 TDP 为 ML 团队提供什么,以及如何通过阅读我们的购买者指南为您的团队选择最好的。
通过模型辅助标签实现自动化
准确注释实现全面数据集所需的数万甚至数百万资产已经阻止了许多有前途的人工智能计划达到生产就绪模型。这就是为什么通过模型辅助标签实现自动化是减少宝贵资本浪费的最简单方法之一。模型辅助标注使用您自己的模型使标注更容易、更准确、更快。在某些情况下,我们看到 ML 团队通过使用这种方法节省了 50-70% 的整个标签预算。

利用主动学习并优先考虑正确的数据
通过采用主动学习和优先处理正确的数据,您的团队可以显着提高生产力和效率。我们已经看到客户通过管理他们的数据集将他们的迭代周期缩短了 8 倍,并使用更少的训练数据。主动学习的数据选择通常涉及选择稀有数据或困难案例。在稀有数据的情况下,模型需要最少数量的示例才能在所选任务上表现良好。如果没有足够数量的示例来为模型提供数据,那么随机采样数据可能效率太低。使用带有模型嵌入的相似性函数等工具可以帮助您发现更多匹配的数据示例。团队可以通过使用模型嵌入直观地发现模式并识别数据中的边缘情况. 通过对视觉上相似的数据进行聚类,团队可以更好地了解模型性能和数据分布的趋势。虽然团队可以手动计算和绘制集群,但 ML 中的一些用例需要对时间更敏感的趋势检测和更快的方法。这就是视觉嵌入工具有助于提高模型性能和支持主动学习工作流程的地方。


时间:2022-12-04 00:47 来源:未知 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
















