一文理清深度学习前馈神经网络
Index
- 多层感知机(MLP)介绍
- 深度神经网络的激活函数
- 深度神经网络的损失函数
- 多层感知机的反向传播算法
- 神经网络的训练技巧
- 深度卷积神经网络
前馈神经网络(feedforward neural network)是一种最简单的神经网络,各神经元分层排列。每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层.各层间没有反馈。是目前应用最广泛、发展最迅速的人工神经网络之一。研究从20世纪60年代开始,目前理论研究和实际应用达到了很高的水平。
——百度百科
而深度学习模型,类似的模型统称是叫深度前馈网络(Deep Feedforward Network),其目标是拟合某个函数f,由于从输入到输出的过程中不存在与模型自身的反馈连接,因此被称为“前馈”。常见的深度前馈网络有:多层感知机、自编码器、限制玻尔兹曼机、卷积神经网络等等。
01 多层感知机(MLP)介绍
说起多层感知器(Multi-Later Perceptron),不得不先介绍下单层感知器(Single Layer Perceptron),它是最简单的神经网络,包含了输入层和输出层,没有所谓的中间层(隐含层),可看下图:
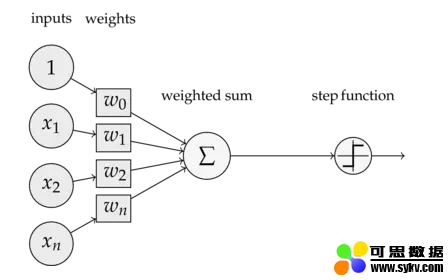
也就是说,将输入向量赋予不同的权重向量,整合后加起来,并通过激活函数输出1或-1,一般单层感知机只能解决线性可分的问题,如下图:
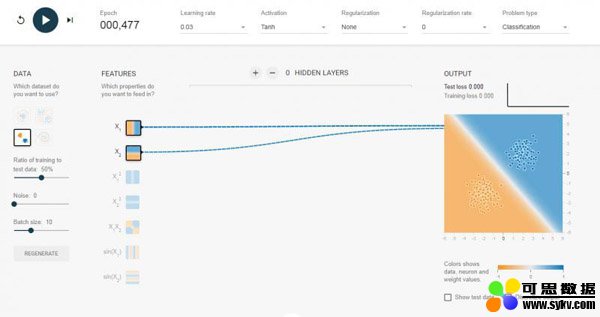
我选择了0个隐含层,也就是我们介绍的单层感知机,对于可以线性可分的数据,效果还是可以的。如果我换成线性不可分的数据集,如下图,那么跑半天都跑不出个什么结果来。
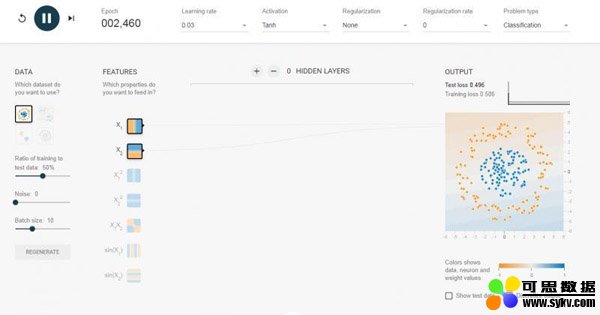
这个时候就引入多层感知器,它相比单层感知器多了一个隐含层的东西,同样的数据集,我加入两层 隐含层,瞬间就可以被分类得很好。
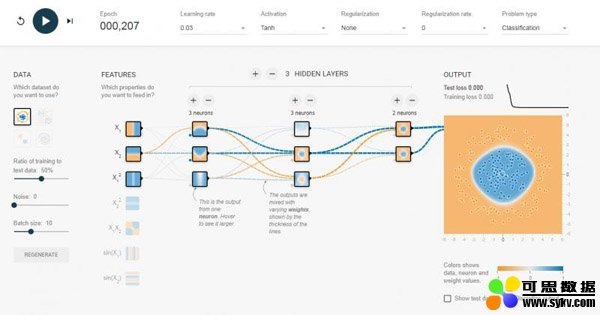
对于上面直观的了解,我这里还是要深入介绍一下多层感知机的原理。Multi-Layer Perceptron(我们后面都叫MLP),MLP并没有规定隐含层的数量,因此我们可以根据自己的需求选择合适的层数,也对输出层神经元没有个数限制。
02 深度神经网络的激活函数
感知机算法中包含了前向传播(FP)和反向传播(BP)算法,但在介绍它们之前,我们先来了解一下深度神经网络的激活函数。
为了解决非线性的分类或回归问题,我们的激活函数必须是非线性的函数,另外我们使用基于梯度的方式来训练模型,因此激活函数也必须是连续可导的。 @ 磐创 AI
常用的激活函数主要是:
Sigmoid激活函数
Sigmoid函数就是Logistic函数,其数学表达式为:
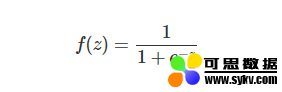
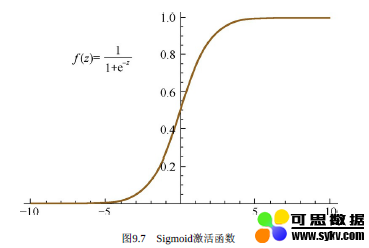
对应函数图像为:
对应的导函数为:
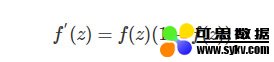
可以看出,Sigmoid激活函数在定义域上是单调递增的,越靠近两端变化越平缓,而这会导致我们在使用BP算法的时候出现梯度消失的问题。
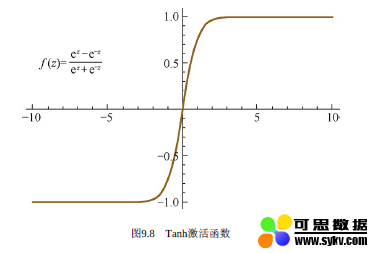
Tanh激活函数
Tanh激活函数中文名叫双曲正切激活函数,其数学表达式为:
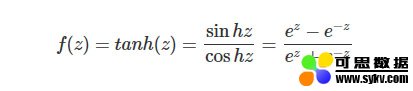
对应函数图像为:
对应的导函数为:
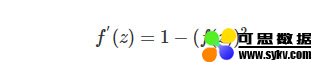
同样的,tanh激活函数和sigmoid激活函数一样存在梯度消失的问题,但是tanh激活函数整体效果会优于Sigmoid激活函数。
Q:为什么Sigmoid和Tanh激活函数会出现梯度消失的现象?
A:两者在z很大(正无穷)或者很小(负无穷)的时候,其导函数都会趋近于0,造成梯度消失的现象。
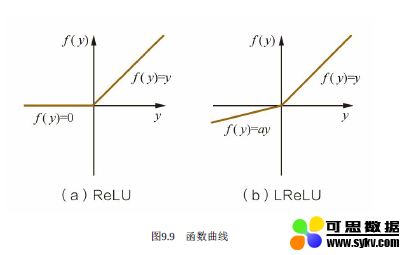
ReLU激活函数
ReLU激活函数又称为修正线性单元或整流性单元函数,是目前使用比较多的激活函数,其数学表达式为:

对应函数图像为(a):
对应的导函数为:
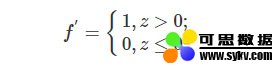
ReLU激活函数的收敛速度要比上面两种要快得多,ReLU激活函数的X轴左侧值恒为0,使得网络具有一定的稀疏性,从而减少参数之间的依存关系,缓解了过拟合的情况,而且它的导函数有部分为常数1,因此不存在梯度消失的问题。但ReLU激活函数也有弊端,那就是会丢失一些特征信息。
LReLU激活函数
上面可以看到LReLU激活函数的图像了,它和ReLU激活函数的区别在于当z<0时,其值不为0,而是一个斜率为a的线性函数(一般a会是一个十分小的正数),这样子即起到了单侧抑制,也不完全丢失负梯度信息,其导函数表达式为:
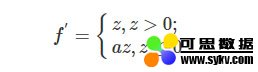
03 深度神经网络的损失函数
损失函数(Loss Function)又被称为Cost Function,作用是用来表示预测值与真实值之间的误差,深度学习模型的训练是基于梯度的方法最小化Loss Function的过程,下面就介绍几种常见的损失函数。
均方误差损失函数
均方误差(Mean Squared Error,MSE)是比较常用的损失函数,其数学表达式如下:
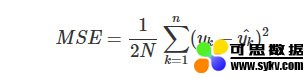
交叉熵损失函数
交叉熵(Crocs Entropy)损失函数使用训练数据的预测值与真实值之间的交叉熵来作为损失函数,其数学表达式如下:
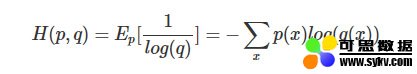
适用场景
一般来说,MSE更适合输出值为连续值,并且最后一层不含Sigmoid或Softmax激活函数的神经网络;而交叉熵则适合二分类或者多分类的场景。
04 多层感知机的反向传播算法
在MLP中,输入信号通过各个网络层的隐节点产生输出的过程,我们称之为“前向传播“,而前向传播最终是产生一个标量损失函数。而反向传播算法(Backpropagation)则是将损失函数的信息沿着网络层向后传播用以计算梯度,达到优化网络参数的目的。
05 神经网络的训练技巧
神经网络的训练,常常会遇到的问题就是过拟合,而解决过拟合问题的方法也有很多,简单罗列下:Data Augmentation(数据增广)、Regularization(正则化)、Model Ensemble(模型集成)、Dropout等等。此外,训练深度学习网络还有学习率、权重衰减系数、Dropout比例的调参等。还有Batch Normalization,BN(批量归一化)也可以加速训练过程的收敛,有效规避复杂参数对网络训练效率的影响。
Data Augmentation
Data Augmentation也就是数据增广的意思,就是在不改变数据类别的情况下,这里主要针对图像数据来说,主要包括但不限于:
1)角度旋转
2)随机裁剪
3)颜色抖动:指的是对颜色的数据增强,包括图像亮度、饱和度、对比度变化等
4)增加噪声:主要是高斯噪声,在图像中随机加入
5)水平翻转
6)竖直翻转
参数初始化
考虑到全连接的深度神经网络,同一层中的任意神经元都是同构的,所以拥有相同的输入和输出,如果参数全部初始化为同一个值,无论是前向传播还是反向传播的取值都会是一样的,学习的过程将无法打破这种情况。因此,我们需要随机地初始化神经网络的参数值,简单的一般会在
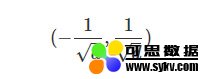
的均匀分布中去随机抽取,其中d是一个神经元接受的输入维度。
学习率
学习率我们通常设为0.1,但是如果在实践中验证集上的loss或者accuracy不变的时候,可以考虑增加2~5倍的学习率。
Dropout原理
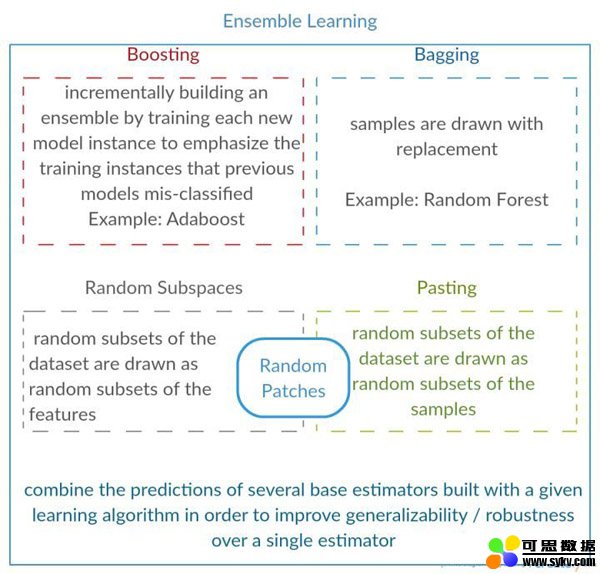
Dropout在深度学习网络训练中是十分常用的,指的是以一定的概率p随机丢弃一部分神经元节点,而这个“丢弃”只是临时的,是针对每一次小批量的训练数据而言,由于是随机丢弃,所以每一次的神经网络结构都会不一样,相当于每次迭代都是在训练不同结构的神经网络,有点像传统机器学习中的Bagging方法。
具体实现上,在训练过程中,神经元的节点激活值以一定的概率p被“丢弃”,也就是“停工”。因此,对于包含N个神经元节点的网络,在Dropout的作用下可以看做是生成 2的N次方个模型的集合,这个过程会减弱全体神经元之间的联合适应性,减少过拟合的风险,增强泛化能力。
Batch Normalization原理
因为神经网络的训练过程本质就是对数据分布的学习,因此训练前对输入数据进行归一化处理显得很重要。我们知道,神经网络有很多层,每经过一个隐含层,训练数据的分布会因为参数的变化而发生改变,导致网络在每次迭代中都需要拟合不同的数据分布,这样子会增加训练的复杂度以及过拟合的风险。
因此我们需要对数据进行归一化处理(均值为0,标准差为1),把数据分布强制统一再一个数据分布下,而且这一步不是一开始做的,而是在每次进行下一层之前都需要做的。也就是说,在网路的每一层输入之前增加一个当前数据归一化处理,然后再输入到下一层网路中去训练。
Regularizations(正则化)
这个我们见多了,一般就是L1、L2比较常见,也是用来防止过拟合的。
L1正则化会使得权重向量w在优化期间变得稀疏(例如非常接近零向量)。 带有L1正则化项结尾的神经网络仅仅使用它的最重要的并且接近常量的噪声的输入的一个稀疏的子集。相比之下,最终的权重向量从L2正则化通常是分散的、小数字。在实践中,如果你不关心明确的特征选择,可以预计L2正则化在L1的性能优越。
L2正则化也许是最常用的正则化的形式。它可以通过将模型中所有的参数的平方级作为惩罚项加入到目标函数(objective)中来实现,L2正则化对尖峰向量的惩罚很强,并且倾向于分散权重的向量。
Model Ensemble(模型集成)
模型集成在现实中很常用,通俗来说就是针对一个目标,训练多个模型,并将各个模型的预测结果进行加权,输出最后结果。主要有3种方式:
1)相同模型,不同的初始化参数;
2)集成几个在验证集上表现效果较好的模型;
3)直接采用相关的Boosting和Bagging算法。
06 深度卷积神经网络(CNN)
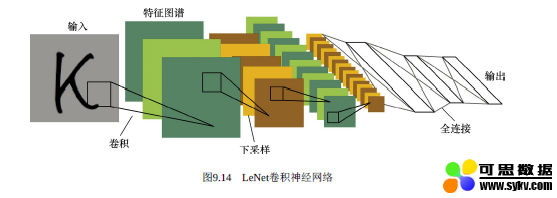
终于来到了我们耳熟能详的CNN了,也就是卷积神经网络(Convolutional Neural Network,CNN),它也是属于前馈神经网络的一种,其特点是每层的神经元节点只响应前一层局部区域范围内的神经元(全连接网络中每个神经元节点则是响应前一层的全部节点)。
一个深度卷积神经网络模型,一般由若干卷积层叠加若干全连接层组成,中间包含各种的非线性操作、池化操作。卷积运算主要用于处理网格结构的数据,因此CNN天生对图像数据的分析与处理有着优势,简单地来理解,那就是CNN是利用滤波器(Filter)将相邻像素之间的轮廓过滤出来。
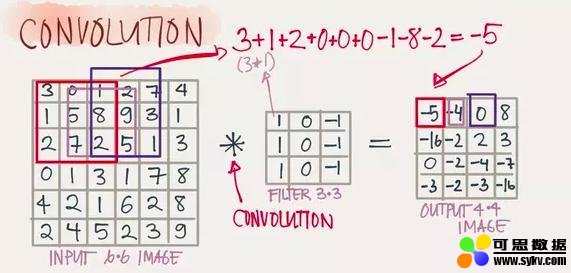
Convolution(卷积)
卷积的滤波器(Filter)我们可以看做是一个window,可以观察下面的案例,有一个6X6的网络以及一个3X3的Filter,其中Filter的每个格子上有权值。拿着FIlter在网络上去移动,直到所有的小格子都被覆盖到,每次移动,都将Filter“观察”到的内容,与之权值相乘作为结果输出。最后,我们可以得到一个4X4的网格矩阵。(下面的6张图来自参考文献5,侵删)
Padding(填充)
卷积后的矩阵大小与一开始的不一致,那么我们需要对边缘进行填充,以保证尺寸一致。
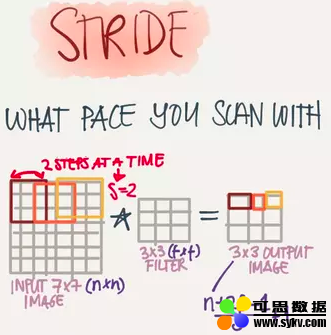
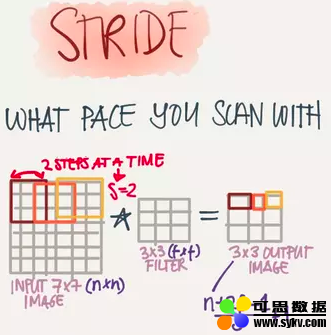
Stride(步长)
也就是Filter移动的步伐大小,上面的例子为1,其实可以由我们自己来指定,有点像是学习率。
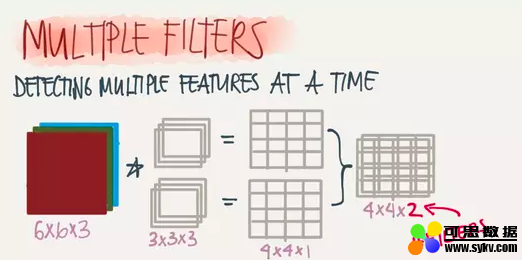
Depth(深度)
深度指的是图片的深度,一张6X6X3大小的图片经过3X3X3的Filter过滤后会得到一个4X4X1大小的图片,因此深度为1。我们也可以通过增加Filter的个数来增加深度,如下:
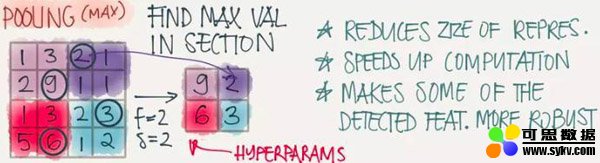
Pooling(池化)
因为滤波器在进行窗口移动的过程中会有很多冗余计算,效率很慢,池化操作的目的在于加速卷积操作,最常用的有Maxpooling,其原理如下图所示:
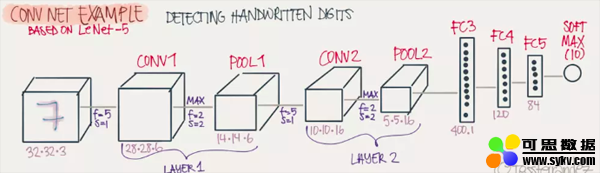
完整的深度CNN网络
卷积操作的本质
1)Sparse Interaction(稀疏交互)
因为卷积核的尺度会小于输入的维度,也就是我们的FIlter会小于网络大小一样,这样子每个输出神经元仅仅会与部分特定局部区域内的神经元存在连接权重(也就是产生交互),这种操作特性我们就叫稀疏交互。稀疏交互会把时间复杂度减少好几个数量级,同时对过拟合的情况也有一定的改善。
2)Parameter Sharing(参数共享)
指的是在同一个模型的不同模块使用相同的参数,它是卷积运算的固有属性。和我们上面说的Filter上的权值大小应用于所有网格一样。

时间:2020-02-06 21:52 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
















