五行代码用图提升模型表现,TensorFlow开源NSL神经结构学习框架
今日,谷歌 TensorFlow 宣布推出神经结构学习(NSL)开源框架,它使用神经图学习方法来训练带有图和结构化数据的神经网络。
据谷歌 TensorFlow 博客介绍,NSL 是一个新手和高级开发人员都可以用来训练具有结构化信号神经网络的简易框架,可用于构建精确且稳健的视觉、语言理解和预测模型。
- 项目地址:https://github.com/tensorflow/neural-structured-learning
结构化数据包含样本之间丰富的关系信息,许多机器学习任务都得益于此。例如,建模引用网络、句子语言学结构的知识图推断与推理,以及学习分子指纹,这些都需要模型来学习结构化输入,而不只是个别样本。
这些结构可以是明确给出的(例如,作为图形),或者隐式推断的(例如,作为对抗性示例)。在训练阶段利用结构化信号可以使开发人员获得更高的模型准确度,尤其是当标记数据量相对较小时。谷歌的研究表明,使用结构化信号进行训练也可以带来更稳健的模型。
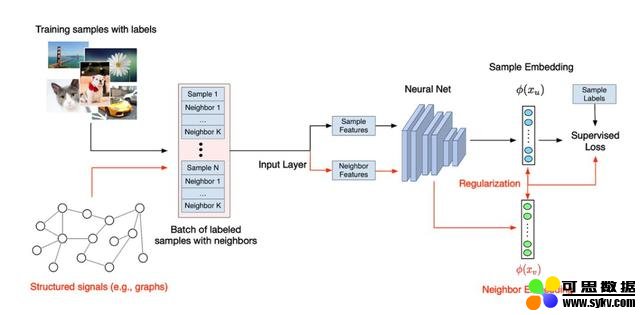
图网络学习的一般流程。
使用这些技术,谷歌极大的提升了模型性能,例如学习图像语义嵌入。
神经结构学习(NSL)是一种用于训练具有结构化信号深度神经网络的开源框架。它实现了谷歌在论文《Neural Graph Learning: Training Neural Networks Using Graphs》中介绍的神经图学习,使开发人员能够使用图训练神经网络。
这里的图可以是多样的,例如知识图、医疗记录、基因组数据或多模式关系(例如,图像 - 文本对)。此外,NSL 还可以应用到对抗性学习,也就是说输入样本之间的结构可以是使用对抗性扰动动态构建的。
NSL 让 TensorFlow 用户能够轻松地结合各种结构化信号来训练神经网络,且适用于不同的学习场景:监督、半监督和无监督(表示)设置。
NSL 如何工作
在 NSL 框架中,结构化信息(如可以定义为图的数据或隐性的对抗样本),都可以被用来归一化神经网络的训练,使得模型学习精确地进行预测(通过最小化监督损失)。同时,保证从同一种结构中的所有输入保持同样的相似度(通过最小化近邻损失)。这种技术是可以泛化的,可以使用在神经网络架构上,如前向神经网络、卷积神经网络和循环神经网络等。
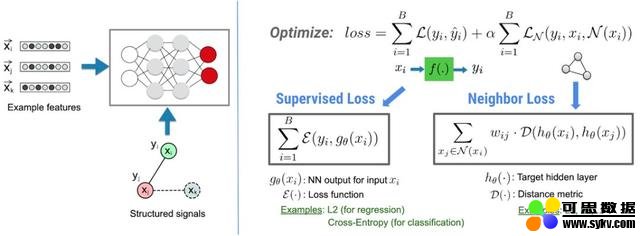
NSL 的基本架构。
用 NSL 建立一个模型
有了 NSL,建立一个使用结构化数据的模型就会很容易,而且非常直观。给定一个图(有具体结构)和训练样本,NSL 提供了相关的工具,用于将这些样本输入到 TFRcords 中,用于降采样操作。
具体代码如下,可以使用相关的命令行工具将图和数据进行输入:
- python pack_nbrs.py --max_nbrs=5 \
- labeled_data.tfr \
- unlabeled_data.tfr \
- graph.tsv \
- merged_examples.tfr
之后,NSL 提供了一些 API,可以将定制化的模型「打包起来」,将处理过的样本输入进去,使用图结构进行归一化操作。以下为具体代码:
- import neural_structured_learning as nsl
- # Create a custom model — sequential, functional, or subclass.
- base_model = tf.keras.Sequential(…)
- # Wrap the custom model with graph regularization.
- graph_config = nsl.configs.GraphRegConfig(
- neighbor_config=nsl.configs.GraphNeighborConfig(max_neighbors=1))
- graph_model = nsl.keras.GraphRegularization(base_model, graph_config)
- # Compile, train, and evaluate.
- graph_model.compile(optimizer=’adam’,
- loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[‘accuracy’])
- graph_model.fit(train_dataset, epochs=5)
- graph_model.evaluate(test_dataset)
只需要额外的 5 行代码(包括注释),NSL 就可以将一个神经模型和图信号结合起来。从数据上来说,使用图结构可以让模型在训练中使用更少的标注数据,而且不会损失太多的准确率(和原有的监督学习相比只少 10% 甚至是 1%)。
使用没有显式结构的图进行训练
如果没有显形结构的图、或者不是作为输入的情况下,NSL 怎么训练呢?NSL 提供了相关的工具,用于从原始数据中建立一个图。另外,NSL 提供了相关的工具,用于从隐性结构信号中「推导」出对抗样本。对抗样本用于故意诱导模型,使得训练出的模型对于小的输入扰动更为鲁棒。以下为相关代码:
- import neural_structured_learning as nsl # Create a custom model — sequential, functional, or subclass.
- base_model = tf.keras.Sequential(…)# Wrap the custom model with graph regularization.
- graph_config = nsl.configs.GraphRegConfig(
- neighbor_config = nsl.configs.GraphNeighborConfig(max_neighbors=1))
- graph_model = nsl.keras.GraphRegularization(base_model, graph_config) # Compile, train, and evaluate.
- graph_model.compile(optimizer=’adam’,
- loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[‘accuracy’])
- graph_model.fit(train_dataset, epochs=5)
- graph_model.evaluate(test_dataset)
通过少于额外 5 行代码(包括注释),就能获得一个使用带有隐性结构对抗样本训练的神经模型。根据经验,在没有对抗性样本的情况下,当将具有恶意但人类无法检测出的扰动数据添加到输入时,模型会遭受显著的准确度损失(例如,低 30%),加入对抗样本进行训练则可以避免这样的问题。

时间:2019-09-08 22:18 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]使用PyTorch进行知识蒸馏的代码示例
- [机器学习]机器学习中分类任务的常用评估指标和Python代码实现
- [机器学习]深度神经网络模型训练中的 tricks(原理与代码汇
- [机器学习]LDA主题模型 | 原理详解与代码实战
- [机器学习]深度神经网络可解释性方法汇总,附Tensorflow代码实现
- [机器学习]10分钟带你打开深度学习大门,代码已开源
- [机器学习]DL时代的代码补全利器,效果远超语言模型
- [机器学习]让你的GPU为深度学习做好准备(附代码)
- [机器学习]< 机器学习实战 高清中英 源代码 > 分享
- [机器学习]利用深度学习自动补全 Python 代码,这个开源项目有点牛
相关推荐:
网友评论:
















