生产环境中轻松部署深度学习模型
能从数据中学习,识别模式并在极少需要人为干预的情况下做出决策的系统令人兴奋。深度学习是一种使用神经网络的机器学习,正迅速成为解决对象分类到推荐系统等许多不同计算问题的有效工具。然而,将经过训练的神经网络部署到应用程序和服务中可能会给基础设施经理带来挑战。多个框架、未充分利用的基础设施和缺乏标准实施,这些挑战甚至可能导致AI项目失败。本文探讨了如何应对这些挑战,并在数据中心或云端将深度学习模型部署到生产环境。
一般来说,我们应用开发人员与数据科学家和IT部门合作,将AI模型部署到生产环境。数据科学家使用特定的框架来训练面向众多使用场景的机器/深度学习模型。我们将经过训练的模型整合到为解决业务问题而开发的应用程序中。然后,IT运营团队在数据中心或云端运行和管理已部署的应用程序。
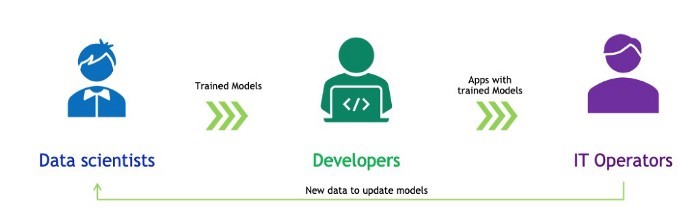
图1.
将深度学习模型部署到生产环境面临两大挑战:
- 我们需要支持多种不同的框架和模型,这导致开发复杂性,还存在工作流问题。数据科学家开发基于新算法和新数据的新模型,我们需要不断更新生产环境。
- 如果我们使用英伟达GPU提供出众的推理性能,有几点要牢记。首先,GPU是强大的计算资源,每GPU运行一个模型可能效率低下。在单个GPU上运行多个模型不会自动并发运行这些模型以尽量提高GPU利用率。
那么我们如何是好?不妨看看我们如何使用英伟达的TensorRT Inference Server之类的应用程序来应对这些挑战。你可以从英伟达NGC库(https://ngc.nvidia.com/catalog/containers/nvidia:tensorrtserver)作为容器,或者从GitHub(https://github.com/NVIDIA/tensorrt-inference-server)作为开源代码来下载TensorRT Inference Server。
TensorRT Inference Server:使部署更容易
TensorRT Inference Server通过以下功能组合,简化部署经过训练的神经网络:
- 支持多种框架模型:我们可以使用TensorRT Inference Server的模型库克服第一个挑战,该模型库是个存储位置,用任何框架(TensorFlow、TensorRT、ONNX、PyTorch、Caffe、Chainer、MXNet甚至自定义框架)开发的模型都可以存储在此处。TensorRT Inference Server可以部署用所有这些框架构建的模型;Inference Server容器在GPU或CPU服务器上启动时,它将所有模型从模型库加载到内存中。然后,该应用程序使用API调用推理服务器对模型运行推理。如果我们有很多无法装入到内存中的模型,可以将单个库拆分成多个库,并运行TensorRT Inference Server的不同实例,每个实例指向不同的库。即使在推理服务器和我们的应用程序运行时,也可以通过改变模型库来轻松更新、添加或删除模型。
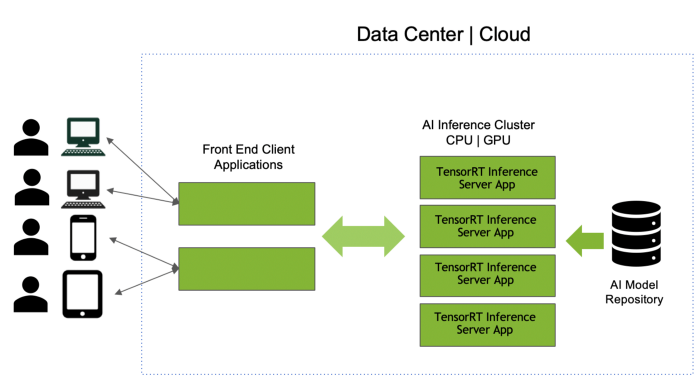
图2
- 尽量提高GPU利用率:我们已成功地运行应用程序和推理服务器,现可以克服第二个挑战。GPU利用率常常是基础设施经理眼里的关键绩效指标(KPI)。TensorRT Inference Server可以在GPU上并发调度多个相同或不同的模型;它可自动尽量提高GPU利用率。因此,我们开发人员不必采取特殊措施,IT运营要求也得到满足。IT运营团队将在所有服务器上运行同样的TensorRT Inference Server容器,而不是在每台服务器上部署一个模型。由于它支持多个模型,因此相比每台服务器一个模型这种场景,可确保GPU充分利用,并使服务器的负载更均衡。这个演示视频(https://youtu.be/1DUqD3zMwB4)解释了服务器负载均衡和利用率。
- 启用实时和批推理:推理有两种。如果我们的应用程序需要实时响应用户,那么推理也需要实时完成。由于延迟是个问题,请求无法放入队列、与其他请求一起批处理。另一方面,如果没有实时要求,可以将请求与其他请求进行批处理,以提高GPU利用率和吞吐量。
我们开发应用程序时,有必要了解实时要求。TensorRT Inference Server有个参数可以为实时应用程序设置延迟阈值,还支持动态批处理,它可以设为非零数字,以实施批处理。我们要与IT运营团队密切合作,确保这些参数正确设置。
- CPU、GPU和异构集群上的推理:在许多企业,GPU主要用于训练。推理在常规CPU服务器上完成。然而,在GPU上运行推理大大加快速度,我们还需要灵活地在任何处理器上运行模型。
不妨探讨如何从CPU推理迁移到GPU推理。
- 我们目前的集群是一组纯CPU服务器,它们都运行TensorRT Inference Server应用程序。
- 我们将GPU服务器引入到该集群,在这些服务器上运行TensorRT Inference Server软件。
- 我们将GPU加速模型添加到模型库中。
- 使用配置文件,我们指示这些服务器上的TensorRT Inference Server使用GPU进行推理。
- 我们可以停用集群中的纯CPU服务器,也可以在异构模式下使用它们。
- 无需对调用TensorRT Inference Server的应用程序更改代码。
- 与DevOps基础设施集成:最后一点与IT团队较为密切。贵公司是否遵循DevOps实践?DevOps是一系列流程和实践,旨在缩短整个软件开发和部署周期。实施DevOps的企业往往使用容器来包装用于部署的应用程序。TensorRT Inference Server是一个Docker容器,IT人员可以使用Kubernetes来管理和扩展它。他们还可以将推理服务器作为Kubeflow管道的一部分,用于端到端的AI工作流程。来自推理服务器的GPU/CPU利用率度量指标告诉Kubernetes何时在新服务器上启动新实例以便扩展。
如果设置模型配置文件,并集成客户端库,很容易将TensorRT Inference Server整合到我们的应用程序代码中。
部署经过训练的神经网络可能带来挑战,不过本文介绍了使这种部署更轻松的若干技巧。欢迎留言交流。

时间:2019-08-08 18:12 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
















