面部识别系统存在哪些「偏见」困境?这名年轻人的发言让 Jeff Dean 忍不住点赞
AI 算法偏见(性别、人种……)如今在海外早已不是新鲜议题,不久前,推特上的一条视频就引发了大众对此大规模的探讨。一名年轻的微软研究人员就此话题在个人推特上展开了对面部识别系统模型所存在偏见的探讨,引发了包括 Jeff Dean 等大牛在内的共鸣。她究竟说了些什么?

事情起源于推特上的一个视频,在视频中,社会党众议员 Alexandria Ocasio-Cortez 声称由数学驱动的算法本质上都是拥有种族主义倾向的。这条帖子很快获得了大众的响应,其中就包括一位名叫 Anna S. Roth 的研究人员。
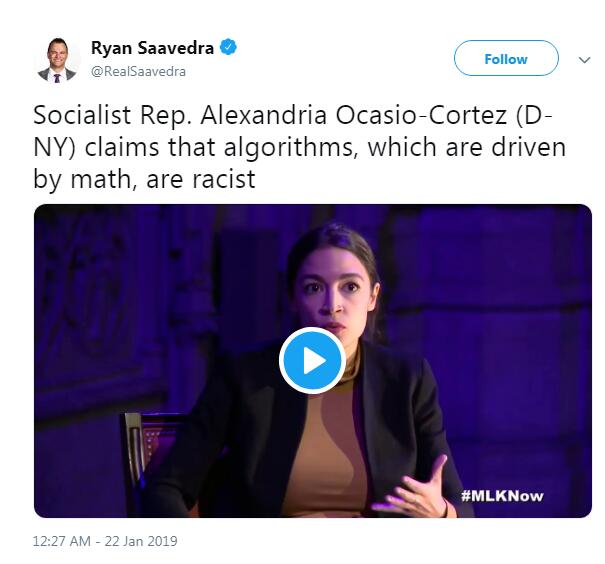
原帖转发量截止目前为止已经达到了 2.8k,拥有超过 7.2k 的留言。
推特直通车:https://twitter.com/RealSaavedra/status/1087627739861897216
据个人主页介绍, Anna S. Roth 是微软技术与研究部门的一名研究人员,专职于微软的 Project Oxford 项目——这是一个混合了 APIs 与 SDKs,使开发人员能够轻松利用 Microsoft Research 和 Bing 的计算机视觉、语音检测和语言理解前沿工作进行再创造的项目。此外,她还曾经入选 Business Insider 杂志「30 位 30 岁以下具有影响力的科技女性」榜单。
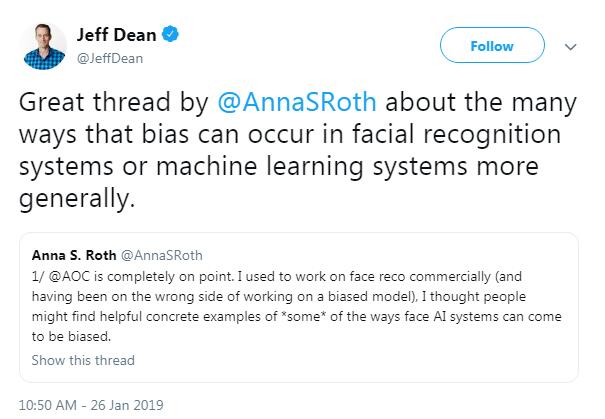
她在个人推特上接连发表多达 29 条的短评,简单概括了面部识别系统模型产生偏见的原因,以及相应的解决方案和现存困境。由于内容浅显易懂且直中要害,谷歌大脑领导人 Jeff Dean 也忍不住在推特上进行推荐。
接下来一起看看 Anna S. Roth 分别说了些什么吧。
关于数据偏差问题
Alexandria Ocasio-Cortez 说的完全在理。我曾经从事面部识别的商业开发工作(当时的方向有点偏,开发的是存在偏见的模型),我认为人们最终会找到一些具体可信的例子搞清 AI 系统是如何产生偏见的。推特上的专家们解释了,面部识别系统之所以产生偏见,是因为数据有所偏差。
所以我准备和大家谈谈:
(1)那些(有偏差的)数据来自哪里。
(2)偏差测量标准的选择同样事关紧要。
(需要强调一点是,我只是针对行业所发生的一些事情进行泛泛而谈,并非专指本人雇主的某个具体事例。简单来说,这些都只是我的个人意见,不代表雇主的立场。)
最前沿的面部识别系统都需要在「非常庞大」的数据集上进行训练。为达到最佳训练效果,你需要获取同一个人的多张相片。比如当下最大的发布数据集之一——来自 UW 的 MF2,就拥有 672K 的人员信息和 4.7M 的相片。
相关论文链接:
https://homes.cs.washington.edu/~kemelmi/ms.pdf
这些数据主要来源于网络,比如 MF2 数据集的数据就出自 Flickr;另一个数据集 MS-Celeb-1M(https://www.msceleb.org)的 1000 万张图像则是从网上「爬」下来的。需要强调的是,「在公共互联网上流传的照片」并不能够完全代表「世界上的所有人类」。
然而全球的互联网访问量并非均匀分布的。连研究人员也一样。你可能抓取的还是那些以英语作为媒介语的网络资源/视频(记住,您需要获取同一个人的多张照片。)那么我想请问的是,使用 Flickr 的都是哪一些人?在微软名人数据集 MS Celeb 的论文中,说明了数据集中的 100 万个名人有超过 3/4 是女性——所以在判断哪个性别的人群在网上更有名气时,是否就会陷入 Alexandria Ocasio-Cortez 所谓的「自动化假设」陷阱?对此,负责构建数据集的人员一般会通过多种手段进行调整。
一个非常「烧钱」的选择是走进「现实世界」中,通过付费的方式进行数据收集。然而想把这件事情做得「正确」(比如收集数据的地点)、做得「符合伦理道德」(比如是否获得对方同意、公平补偿等),可一点都不简单。然而这些细节却会导致结果存在「巨大」差异。
当然我们还可以拥有其他的数据来源。比如有些人就想到使用嫌疑人照片(呀!又是一个根深蒂固的社会偏见影响数据集+注释的例子)。据我所知,一个处在非美国监控州的国内公司可以访问那些大型政府数据集。(很显然如果你是 FB,还可以访问那些具有更好分布的数据。)
数据集不仅仅是你保存数据 + 进行标注的地方。很多数据集需要人类进一步手动进行注释,一般会通过众包的形式(即通过在线平台零碎地给众包人员支付费用,而且往往金额较小)。众包形式存在太多来自人类的干扰因素。比如众包人员的文化背景?他们是不是被问到实际上属于主观的问题?(年龄、情绪等)
关于数据偏差测量
如今我们达成的一个共识是,有偏差的数据输入将导致有偏见的模型。实际上,我们已经拥有许多很酷的技术方法可以解决训练数据的分布问题。
一般要想评估模型的偏差情况和表现性能,你需要找到方法来进行测量。否则你无法得知模型的偏差原因和偏差程度。打个比方,您也许需要创建一个包含具有各种特征的人员的标签数据集,以便你在组与子组上测试模型的运行情况。
偏差测量需要综合这些人的角度和观点——在哪些问题是重要的以及社会科学层面上可能受到模型影响的人群。打个比方,「如果你戴眼镜,将导致模型表现变得不够准确」要比「如果你是有色人种,将导致模型表现变得糟糕」的危害更小,这是有一定社会原因的。
决定哪些内容需要进行测量、构建测量数据集、发布相关标准,是你构建相关系统时的「明智」选择。因此,当 Alexandria Ocasio-Cortez 说「种族不公被模型传递出来,是因为算法仍由人类掌控」时,她是完全正确的。
从过去到现在,对于这么做可能导致的严重后果,人们已经一次又一次进行记录。详见:http://gendershades.org/。它为致力于解决这些问题的不同人群提供了强而有力的论据。(注:这也意味着国际化与多样性。比如计算机视觉领域的大部分工作都是在中国完成创建和消费。因此这些主题都具有国际化视角。)
相关解决方案
回到 Alexandria Ocasio-Cortez 引发的议论。她给到我们的一点启发是,AI 伦理学并非单纯的「减少偏见的技术方法」或者「应用伦理学」。而是偏见渗入到模型当中、或者模型以不适合的方式被使用、或者循环反馈机制加强偏见,因为这些原因交织而成的新问题。
我经常回想《大西洋》杂志一篇关于德国执法部门调查庇护申请的报道中所出现的这句话。当最终采用这些概率系统的用户将系统的性能归结为「天赐」的,而非人类,将会发生什么事情?
文章链接:
https://www.theatlantic.com/magazine/archive/2018/04/the-refugee-detectives/554090/

「BAMF 的面部识别软件以及由它所绘制的庞大数据库,现在看来像是「天赐的」,一位职员带有敬意地表示道。「我从来从来没见它出过错。」
我试图给出一些实际例子,说明涉及面部的识别能力可能导致什么样的严重后果,以帮助大家理解这个视频的大背景。然而,这些想法实际上都来自学界和公众的倡导。「当下」这个领域正在产生「如此之多」的学术研究,这些都是那些有见识的想法的来源。我们很幸运能够向 @timnitGebru、 @jovialjoy,、@hannawallach,、@mathbabedotorg,、@jennwvaughan 这样的专家们学习。
还有许多来自学术界和社会活动界的领导者们正在就如何记录、理解和减少偏见对人工智能的影响,进而减少人工智能对社会的负面影响,纷纷提出自己的想法。我们可以从这些地方找到这些想法 http://gendershades.org/(对行业实践和公众意识有着巨大的影响),以及这里 https://fatconference.org/index.html
我就以这些话作为本次意见发表的收尾吧。作为一名过去经常投入在面部识别相关研究工作的人,我非常感谢这个领域的专家们,他们的功劳包括发现了我当时所研究系统的严重问题(以及创造性的修复方法)。

时间:2019-03-23 12:02 来源:未知 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器视觉]宠物的面部识别,已经实现了吗?
- [机器视觉]美国将重新立法禁止政府使用面部识别技术
- [机器视觉]你的照片被多少面部识别系统「偷偷」用过?是时候用工具查一查了
- [机器视觉]COVID-19大流行正推动面部识别技术应用
- [机器视觉]美国纽约州禁用面部识别软件
- [机器视觉]一种简单而智能的方法:Python也能进行面部识别
- [机器视觉]人脸识别再遭禁令:隐私与偏见争议未休 美国又一州禁用面部识别软件
- [机器视觉]观点:面部识别——未来之路
- [机器视觉]由于服务器配置错误,导致面部识别公司Clearview源代码公开
- [机器视觉]由于服务器配置错误,导致面部识别公司Clearview源代码公开
相关推荐:
网友评论:
















